Python client
EVA ICS machine learning kit Python library can work both with and with no server installed. If there is no server installed, data is processed on the client side.
Contents
Installation
Workstation/standalone
pip3 install evaics.ml
The above command must be typed in the system terminal. If using Anaconda Navigator, open a terminal window for an environment:
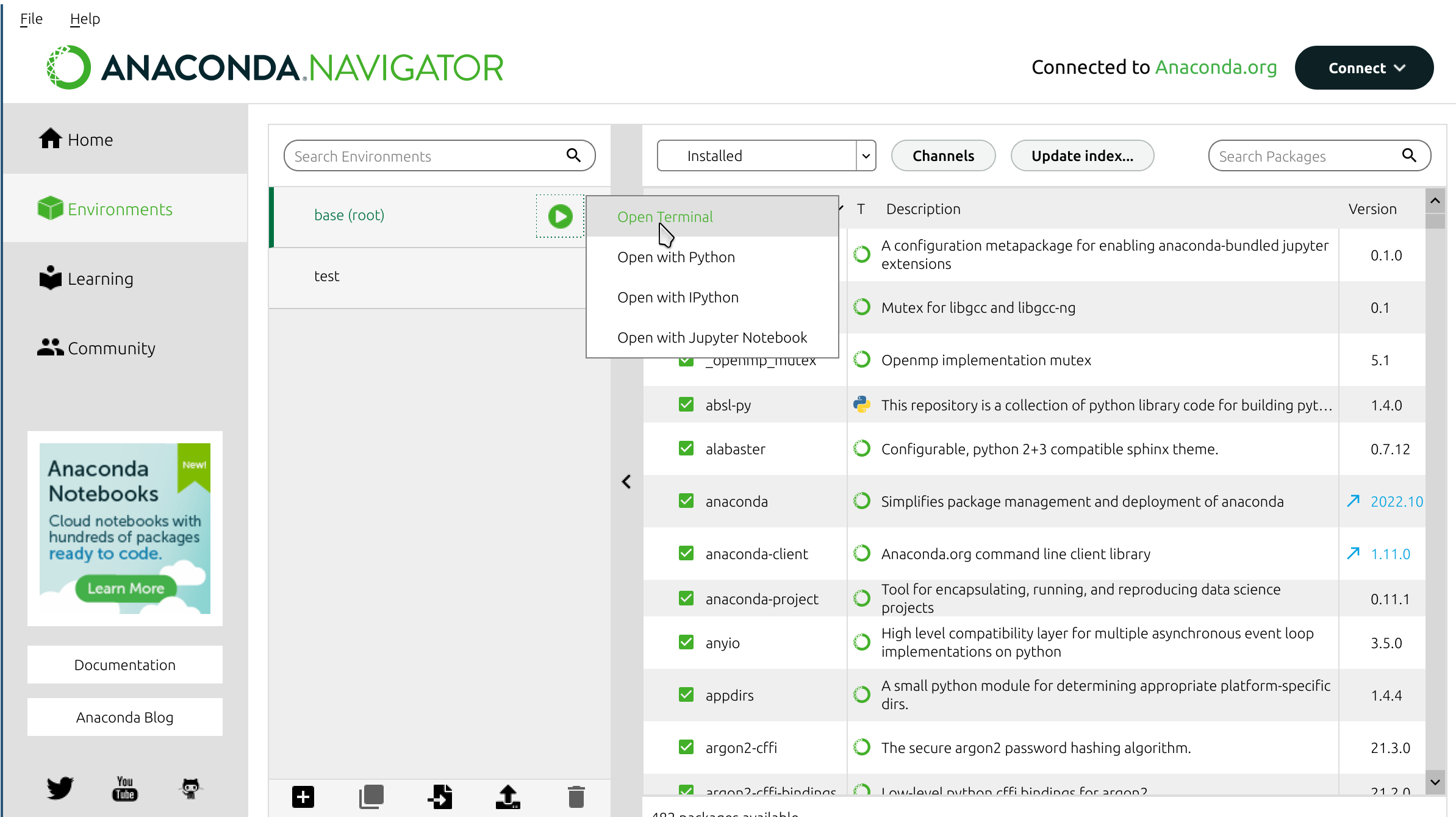
EVA ICS venv
If the module is installed on EVA ICS v4 node, use the following command to add ML kit Python client into EVA ICS venv:
eva venv add evaics.ml
Querying data
HTTP Lazy initialization
from evaics.client import HttpClient
# the import automatically enabled additional client methods
import evaics.ml
client = HttpClient('http://127.0.0.1:7727',
user='operator', password='xxx')
# If Machine learning kit server is used with a front-end and API methods
# are mapped to the same port, the variable can be just set to True.
# If Machine learning kit server is not installed, do not set this
# variable or set it to None
client.mlkit = 'http://127.0.0.1:8811'
# initialize an empty request
req = client.history_df()
BUS/RT Lazy initialization
BUS/RT access requires ML kit server to be deployed.
# initialize BUS/RT if not connected. Not required for EVA ICS Python
# services and Python macros
bus = busrt.client.Client('/opt/eva4/var/bus.ipc', 'test-py')
bus.connect()
client = busrt.rpc.Rpc(bus)
# the name of ML kit server service instance
client.mlkit = 'eva.svc.ml'
# initialize an empty request
req = client.history_df()
Standard initialization
from evaics.client import HttpClient
from evaics.ml import HistoryDF
client = HttpClient('http://127.0.0.1',
user='operator', password='xxx')
# both HTTP and BUS/RT RPC client can be used
req = HistoryDF(client).with_mlkit(True)
OID mapping
with “oid” method item state can fields can be mapped to specific data frame columns. Set True to map field with the default column name (e.g. sensor:tests/temp1/value), a string to specify a custom column name:
req.oid('sensor:tests/temp1', status='temp1st', value='temp1')
If a state field is not required, it can be omitted.
OID mapping from CSV file
A client can read mapping from a CSV file with fields “oid”, “status”, “value” and “database” (can be omitted if ML kit server is used). This can be done either with specifying “params_csv” argument in the request constructor or calling “read_params_csv” request method:
req = client.history_df(params_csv='params_csv')
# or
req = HistoryDF(client, params_csv='params.csv')
# or
req = req.read_params_csv('params.csv')
Usage example
All the methods can be called as chained:
result = client.history_df(
params_csv='params.csv').t_start(
'2023-02-22 23:23:34').t_end(
'2023-02-23 03:33:19').fill('10T').fetch(t_col='keep')
Uploading data
Prepare a request the same way as querying (database parameter for OIDs is ignored). Then use “push” method to push a file. The file extension must match:
.arrows for Arrow streams
.arrow for Arrow files
.csv for CSV files
Instead of a file, a pyarrow table can be submitted. The database service can be specified in a short manner (e.g. “id” for “eva.db.id”) or in full. Example:
result = client.history_df(params_csv='params.csv').push(
'path/to/file.csv', database='mydb')
Module API
- class evaics.ml.HistoryDF(client, params_csv: Optional[str] = None)
Fetches data from EVA ICS v4 history databases
When the primary module is imported, the method “history_df()” is automatically added to evaics.client.HttpClient
Create HistoryDF object instance
All configuration methods of the class can be used in chains.
- Parameters
client – HTTP client object
- Optional:
params_csv: CSV file or stream to read parameters from
- database(database: str)
Specify a non-default database
- Parameters
database – database name (db service without eva.db. prefix)
- fetch(t_col: str = 'keep', tz: str = 'local', output='arrow', strict_col_order=True)
Fetch data
- Optional:
output: output format (arrow, pandas or polars) t_col: time column processing, “keep” - keep the column, “drop” - drop the time column tz: time zone (local, custom or None to keep time column as UNIX timestamp), the default is “local” strict_col_order: force strict column ordering (default: True)
- Returns
a prepared Pandas DataFrame object
- fill(fill: str)
Fill the data frame
- Parameters
fill – XN, where X - integer, N - fill type (S for seconds, T for minutes, H for hours, D for days, W for weeks), e.g. 15T for 15 minutes. The values can be rounded to digits after comma as XN:D, e.g 15T:2 - round to 2 digits after comma. The default fill is 1S
- limit(limit: int)
Limit the data frame rows to
- Parameters
limit – max number of rows
- oid(oid: Union[evaics.sdk.OID, str], status=False, value=False, database=None, xopts=None)
Append OID for processing
- Parameters
oid – item OID (string or OID object)
- Optional:
status: True to keep, a string to rename, False to drop value: same behavior as for keep database: db service to query data from (mlkit srv only) xopts: db service extra opts (mlkit srv only)
- push(data, database='default')
Push data
Requires ML kit server
- Options:
data: Pyarrow table, file object or file path database: database svc id (default: default)
- read_params_csv(f: str)
Read OID mapping from a CSV file
CSV file must have the column “oid” and optional ones “status”, “value” and “database”
- Parameters
f – file path or buffer
- t_end(t_end: Union[float, str])
Specify the data frame end time
- Parameters
t_start – a float (timestamp), a string or a datetime object
- t_start(t_start: Union[float, str, datetime.datetime])
Specify the data frame start time
- Parameters
t_start – a float (timestamp), a string or a datetime object
- with_mlkit(mlkit: Union[bool, str])
Set ML kit url/svc name
- Parameters
mlkit – True for the same URL as HMI, svc name or url for other
- xopts(xopts: dict)
Extra database options
- Parameters
xopts – dict of extra options (refer to the EVA ICS database service
info) (documentation for more) –